In this post we are going to introduce an optimization approach from artificial intelligence: Reinforcement Learning (RL).
Hopefully we will convince you that it is both a powerful conceptual framework to organize how to think about digital optimization, as well as a set of useful computational tools to help us solve online optimization problems.
Video Games as Digital Optimization
Here is a fun example of RL from Google’s Deepmind. In the video below, an RL agent learned how to play the classic Atari 2600 game of Breakout. To create the RL agent, Deepmind used a blend of Deep Learning (to map the raw game pixels into a useful feature space) and a type of RL method called Temporal-Difference learning.
The object of Breakout is to remove all of the bricks in the wall by bouncing the ball off of a paddle while ensuring that you don’t miss the ball and let it pass the paddle (lose a life). The only control, or action, to take is to move the paddle left or right. Notice that at first, the RL agent is terrible. It is just making random movements left of right. However, after only a few hours of play it begins to learn, based on the position of the ball, how to move the paddle to take out the bricks. After even more play, the RL agent learns a higher level strategy to remove bricks such that ball can pass through behind the wall, a more efficient way to clear the wall of bricks. This higher level strategy emerges from the agent factoring in the long term effects from each decision on how to move the paddle.
This is the same type of behavior that we want to learn for our multi-touch optimization problems. We want to learn not just what the direct (or last touch) effects are, but also the longer term impact across the set of relevant marketing touch-points.
AB Testing as Building Block to AI
To make sure we are all on the same page, lets start with something we are already familiar with from optimization, AB Testing. AB Testing is often used as a way to decide which is the best experience to present to your customers so that they have the highest probability to achieve a particular objective. In order to smooth the transition from AB testing to thinking about RL, it’s going to be helpful to think about AB testing as having the following elements:
- A touch-point – the place, or state, where we need to make the decision, for example on a web page;
- A decision – this is the set of possible competing experiences to present to the customer (the ‘A’ and ‘B’ in AB Testing); and
- A payoff or objective – this is our goal, or reward, it is often an action we would like the customer to take (buy a product, sign-up etc.)
In the image below we have a decision on a web page where we can either present ‘A’ or ‘B’ to the customer, and the customer can either convert or not convert after being exposed to either ‘A’ or ‘B’.
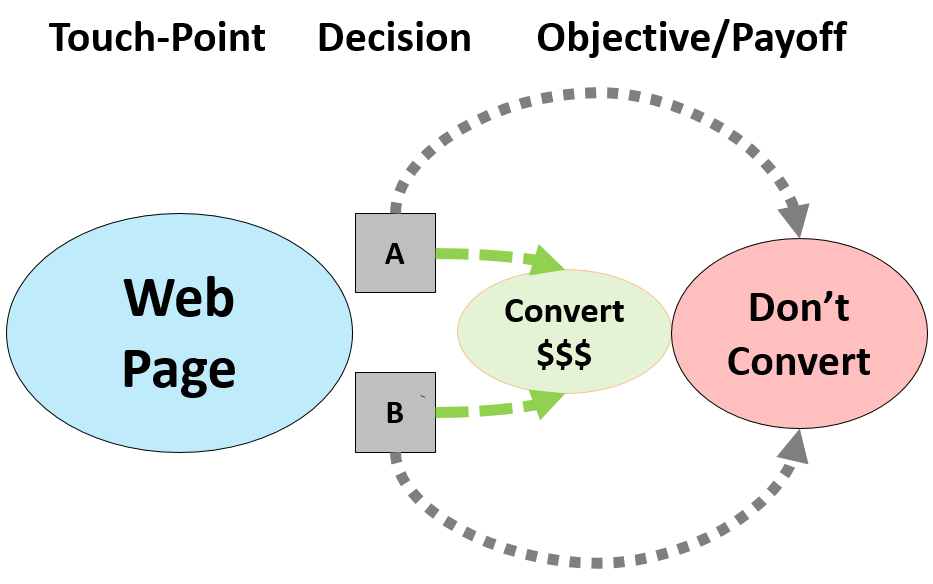
So far, nothing new. Now, lets make this a little more complicated. Instead of making a decision at just one touch-point, let’s add another page where we want to add another set of experiences to test. We now have the following:
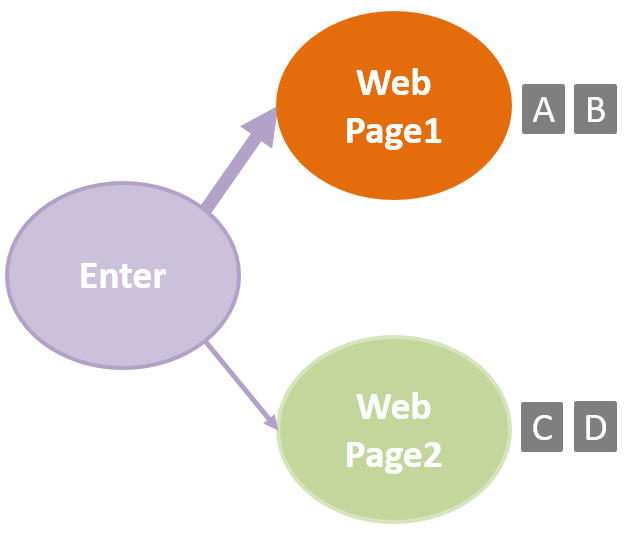
From each of the pages we see that some of the customers will convert (represented by the path through the green circle with ‘$$$’ signs) before exiting the site, while others will directly exit the site without converting (represented by the direct paths to the ‘Exit Site’ node). We could just treat this as two separate AB tests, and just evaluate the conversion from each of our options (‘A’ and ‘B’ on Page 1, and ‘C’ and ‘D’ on Page 2).

Attribution = Dynamics
However, as we go from one touch-point to multiple touch-points we add additional complexity to our problem. Now, not only do we need to keep track of how often users convert before exiting the site after each of our touch-points, but we also need to account for how often they transition from one touch-point to another.
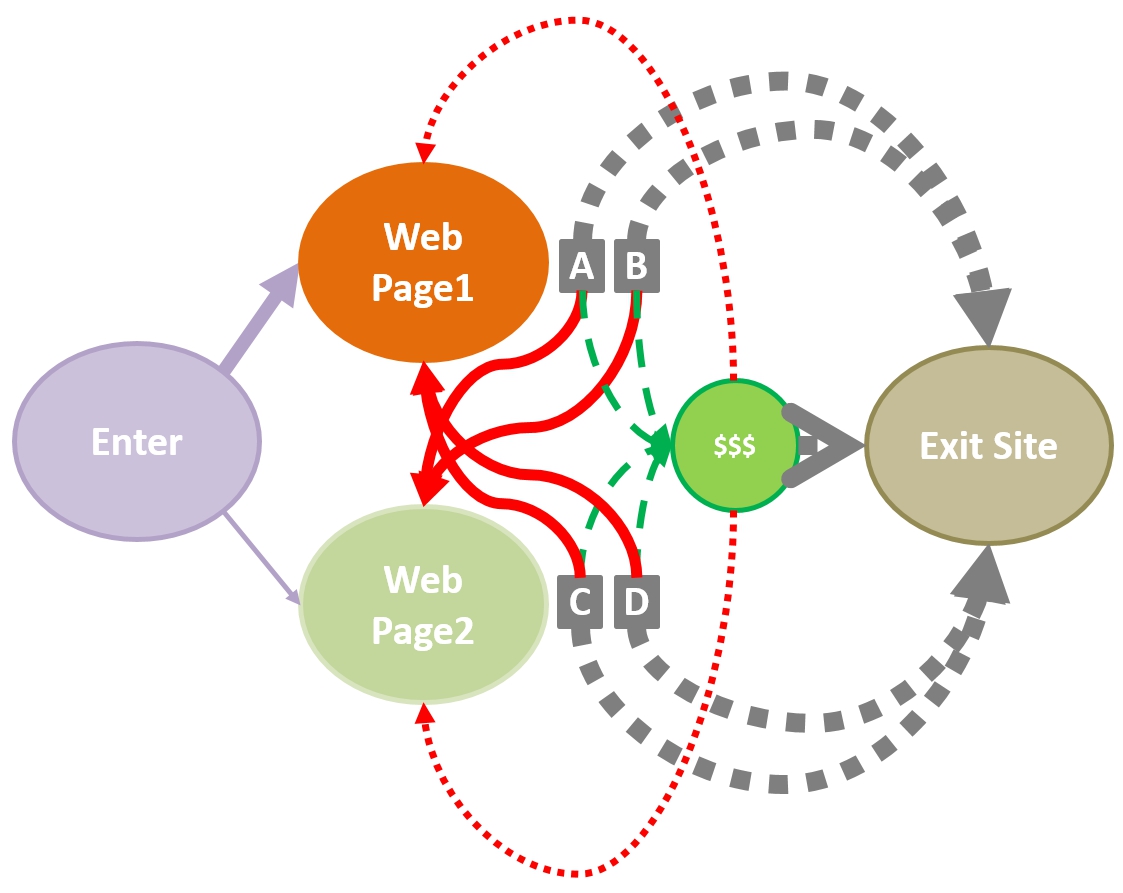
Here, the red lines represent the users that transition from one touch-point to another after being exposed to one of our treatment experiences. These transitions from touch-point to touch-point represent how our experiments are not only affecting the conversion rates, but also how they affect the larger dynamics of our marketing systems.
Accounting for the impact of these changes to the user dynamics is the attribution problem. Attribution is really about accounting for the non-direct impact of our marketing interventions when we no longer just have single decisions, but a system of sequential marketing decisions to consider.
Reinforcement learning
One simple way to handle this is to combine both tests into one multivariate test. In our example, we would have four treatment options: 1) ‘AC’; 2) ‘AD’; 3) ‘BC’; and 4) ‘BD’. However, since not all users will wind up going to each touch-point, users that we assign to ‘AC’ for example, will really be comprised of three groups of users, those exposed to ‘AC’, ‘Aω’, and ‘ωC’, where ‘ω’ represents a null decision. This inefficiency is because this approach doesn’t easily let us take into account the sequential and dynamic nature of our problem, since users may not even wind up being exposed to certain treatments based on how they flow through the process.
This is where reinforcement learning can help us. Realizing that we have sequential decisions, we can recast our AB testing problem as a Reinforcement Learning Problem. From Sutton and Barto:
“Reinforcement learning is learning what to do—how to map situations to
actions—so as to maximize a numerical reward signal. The learner is not
told which actions to take, as in most forms of machine learning, but instead
must discover which actions yield the most reward by trying them. In the most
interesting and challenging cases, actions may affect not only the immediate
reward but also the next situation and, through that, all subsequent rewards.
These two characteristics—trial-and-error search and delayed reward—are the
two most important distinguishing features of reinforcement learning. ” (Page 4 http://people.inf.elte.hu/lorincz/Files/RL_2006/SuttonBook.pdf)
Mapping situations to actions so as to maximize reward by trial and error learning is the marketing optimization problem. RL is so powerful, not only as a machine learning approach, but because it gives us a concise and unified framework to think about experimentation, personalization, and attribution.
Coordinated Bandits through TD-Learning
In our two touch-point problem we have the standard conversion behavior, just like in AB Testing. In addition, we have the transition behavior, where a user can go from one touch-point to another. What would make our attribution problem much easier to solve is if we could just treat the transition behavior like the standard conversion behavior. I like to think of this as a sort of lead-gen model, where each touch point can either try to make the sale directly or pass the customer on to another touch-point in order to close the sale. Just like any other lead -en approach, each decision agent needs to communicate with the others, and credit the leads that are sent its way.
What is cool is that we can use a similar approach that Deepmind uses to treating the transition events like conversion events. This will let us hack our AB Testing, or bandit approach, to solve the multi-touch, credit attribution problem.
Q-Learning
One version of TD-Learning, which is what Deepmind used for Breakout, is Q-Learning. Q-learning uses both the explicit rewards (e.g. the points after removing a brick for example) along with an estimated value of transitioning from touch-point to a new touch-point.
A simple version of the Q-learning (TD(0)) conversion reward looks like:
Reward(t+1)+γ∗Maxa Q(s(t+1),at ).
Don’t let the math throw you. In words,
Reward(t+1) is just the value of conversion event after the user is exposed to a treatment. This is exactly the same thing we measure when we run an AB Test.
Maxa Q(s(t+1),at ) – this is a little trickier, but actually not too tricky. This bit is how we will calculate the long term, attribution calculation. It just says find the highest valued option at the NEW touch-point, and use its value as the credit to attribute back to the selected action from the originating touch-point.
γ – this is really a technicality, it is just a discount rate (its the same type of calculation that banks use in calculating the present value of payments over time). For our example below we will just set γ=1 but normally γ is set between 0 and 1.
Lets run through a quick example to nail this down. Lets go back to our simple two touch-point example. On Page 1 we select either ‘A’ or ‘B’ and on Page 2 we select between ‘C’ or ‘D’. For simplicity’s sake, lets say the first 10 customers go only to Page 1 during their visit. Half of them get exposed to ‘A’ and the other half get exposed to ‘B’. Lets say three customers convert after ‘A’ and only one customer converts after ‘B’. Lets also assume a conversion is worth $1. Based on this traffic and conversions, the estimated values for Page1:A=$3.0/5, or $0.60, and for Page2:B=$1.0/5, or $0.20. So far nothing new. This is exactly the same types of conversion calculations we make all of the time with simple AB Tests (or bandits).
Now, lets say customer 11 comes in, but this time, the customer hits Page2 first. We then randomly pick experience ‘C’. After being exposed to ‘C’, the customer, rather than converting, goes to Page 1. This is where the magic happens. Page 2 now ‘asks’ Page 1 for a reward credit for sending it a customer lead. Page 1 then calculates the owed credit as the value of its highest valued option, which is ‘A’, with a value of $0.60. The value of Page2:C is now equal to $0.60/1, since remember the TD-Reward is calculated as Reward(t+1)+γ∗Maxa Q(s(t+1),at ) = 0 + 1*0.60 = 0.60.
So now we have:
Page1:A=0.6
Page1:B=0.2
Page2:C=0.6
Page2:D=0.0 (no data yet)
Lets say customer 11, now that they are on Page1, is exposed to ‘A’, but they don’t convert and leave the site. We then update the value of Page1:A, $3/6=$0.50. What is interesting is that even though customer 11 didn’t convert, we still were able to increase the value of Page2:C, which makes sense, since in the long term, getting a user to Page1 is worth something (certainly more than ‘0’ as would be the case with a first click attribution method).
While there is more detail, this is mostly all there is to it. By continuously updating the values of each option in this way, our estimates will tend to converge towards the true long term values.
What is awesome is that RL/TD-Learning lets us: 1) blend Optimization with Attribution; 2) calculate a version of time-decay attribution, but only needing to use an augmented version of a last click approach; and 3) interpret the transitions from one touch-point to another as just a sort of intermediate, or internal conversion event.
In a follow up post, we will cover how to include Targeting, so that we can learn the long term value of each touch-point option/action by customer.
If you would like to learn more, please review our Datascience Resources 2 blog post. If you would like to learn more about Conductrics please feel free to reach out to us.
One Trackback
[…] Going from AB Testing to AI: Optimization as Reinforcement Learning (blog post by Matt — not explicitly mentioned in the episode, but highly relevant to the topic!) […]