The hidden risk of scaling experimentation
Over the last few years, the push to scale online experimentation and enterprise A/B testing has become a mandate for most product and data teams. While scaling an experimentation program can be a powerful driver of innovation, speed without direction is just noise. As the volume of tests increases, organizations often fall into a cycle of ‘blind testing’ – and as data collection scales, so does the risk of compromising privacy.
Conductrics CEO, Matt Gershoff, recently published a peer-reviewed paper in Applied Marketing Analytics (Volume 11, Number 3) titled “When less is more: Privacy by design in A/B testing”. The paper addresses an efficient approach to embedding privacy-by-design into experimentation programs without sacrificing advanced statistical capabilities. The benefits of this architecture are twofold: it provides a highly efficient analytical model for running tests at scale, and, by strictly adhering to privacy-by-design principles, it significantly reduces the risk of data breaches.
The risk is not theoretical, especially in highly regulated environments like healthcare and financial services. Consider the April 2025 disclosure from Blue Shield of California. Over three years, data that likely included protected health information for over 4.7 million individuals was mistakenly shared with Google Ads. That data flow was a direct violation of HIPAA regulations, carrying the potential for massive fines and the severe erosion of customer trust.
The traditional approach to mitigating this risk relies on strict corporate policies and governance checklists. But policies can be bypassed, misconfigured, or simply forgotten by a well-meaning engineer trying to ship a test quickly. We believe that trust is the foundation of digital experiences. Safety should not depend entirely on a policy; it must be engineered directly into the architecture itself.
The logic: Engineering privacy by design
To solve the friction between scaling insights and protecting users, we have to look at the core principles of privacy by design (PbD). One of the fundamental concepts underpinning PbD is data minimization – the structural requirement that you use only the data needed, nothing more. This isn’t just a theoretical best practice; it’s an explicit requirement outlined in frameworks like GDPR.
But how do you build a GDPR compliant A/B testing program that scales to the enterprise level while actively minimizing the collection and storage of personally identifiable information (PII)?
In his paper, Matt outlines two key ideas that provide a comprehensive solution:
- Experimentation is fundamentally a regression problem
At its core, most of the statistical analysis required for experimentation can be reduced to a linear regression problem. - Regression models do not require individual-level data
Regression models can be run on aggregated data using appropriate summary statistics. In a happy coincidence, this aggregate data approach aligns nicely with K-anonymity, a simple yet useful privacy engineering approach.
K-anonymity is a formal privacy standard in which data is grouped in such a way that any single individual is indistinguishable from at least K-1 other individuals in the dataset. By aggregating data into a K-anonymous format before it enters the statistical engine, you sever the link to personal identity while entirely preserving the information needed for the test.
Advanced analysis without the PII payload
Adopting data minimization does not mean you have to settle for basic, surface-level metrics. You can optimize personal experiences without exposing sensitive PII.
Because regression serves as the foundation for complex statistical tasks, using K-anonymized data still allows your team to perform advanced, high-fidelity analyses, including:
- Pairwise interactions: Discovering how different experimental variables interact with one another.
- Conditional ATE: Uncovering segment-level average treatment effects to understand exactly how specific user cohorts respond to a variation.
- Variance reduction methods (ANCOVA2/CUPED): Running variance reduction frameworks to enhance test precision and reduce testing time.
You retain the statistical precision required for a mature experimentation program, but you structurally remove the liability and compliance-risks associated with individual-level data.
The payoff: Why data minimization is a competitive advantage
Regulatory compliance and risk mitigation
When it comes to data security, the safest architecture is one that doesn’t hold sensitive data in the first place. You cannot lose what you do not collect. Data minimization is a foundational requirement for privacy by design in regulations such as the GDPR and HIPAA. By enforcing K-anonymity before analysis, we neutralize the explicit risk that causes massive data breaches like the Blue Shield incident.
Customer alignment and intentional learning
Data minimization requires teams to be mindful. Instead of passively collecting everything just in case, it requires intentionality. It forces you to ask exactly how the data you gather will help solve a problem or enrich the customer’s experience. This aligns your optimization strategy with actual customer needs, shifting the focus from blind automation back to intentional learning.
Reducing the shadow costs of warehouse-native tools
There is also a strict engineering advantage to this architecture. Processing individual-level event data for every single test requires massive computational overhead. Many modern, warehouse-native enterprise A/B testing platforms simply push these heavy compute loads directly onto your cloud infrastructure. This creates hidden ‘shadow costs’ that quietly drain your budget as your testing program scales.
Interestingly, this is where privacy engineering and performance engineering converge. As Matt notes in his research, Conductrics arrived at this aggregated data model (K-anonymity) to solve for privacy. However, engineering teams operating at massive scale – such as Netflix – have arrived at the exact same statistical architecture to solve for compute efficiency.
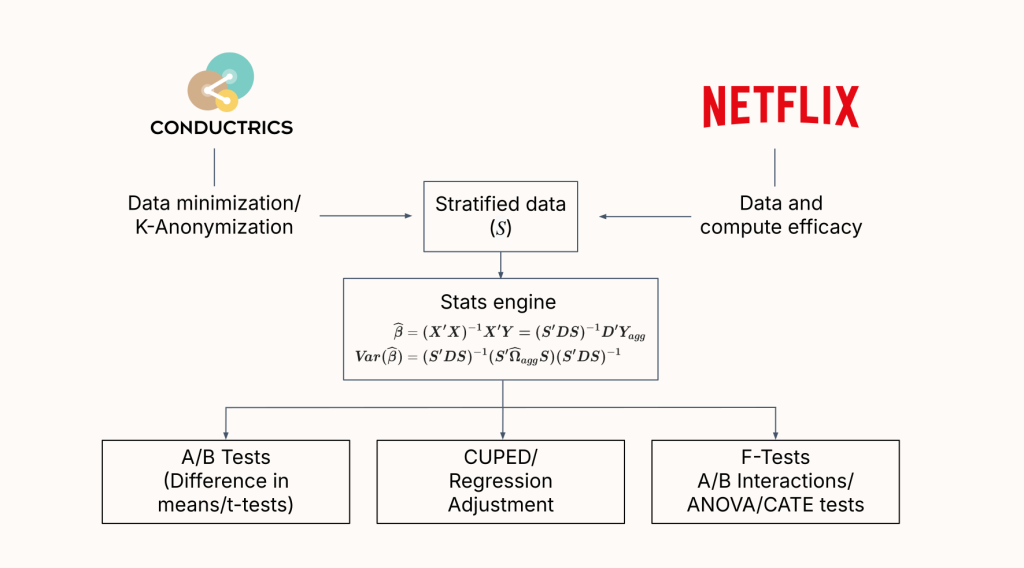
Whether your primary goal is regulatory compliance or simply reducing bloated warehouse compute bills, the mathematical solution is the same. Statistical engines that operate on minimized, aggregated data – such as Conductrics – are inherently faster and more efficient.
Read the paper
If you want to dive into the mathematical mechanics of using K-anonymity for advanced A/B testing, you can read Matt’s full, peer-reviewed paper in Applied Marketing Analytics here: When less is more: Privacy by design in A/B testing.
And if you’re evaluating your current data architecture and want to see how privacy-by-design actually operates in production, we’d be happy to have a technical conversation. We can walk you through exactly how Conductrics handles the statistical heavy lifting without storing individual-level customer data.